I am a M.Sc. student at Nanjing University, advised by Prof. Zongzhang Zhang. Before starting my M.Sc., I received my B.Sc. degree from Nanjing University in 2022 and interned at ByteDance.
My research interest includes reinforcement learning (RL) and generative models, with a particular focus on offline reinforcement learning, which I believe provides a viable path for intelligent decision-making systems. Now I am interested in designing efficient and scalable algorithms by leveraging the power of generative models, such as large language models (LLMs) and diffusion models.
🔥 News
- 2024.03: 🎉🎉 One paper got accepted by ICLR 2024.
📝 Publications

Diffusion Spectral Representation for Reinforcement Learning
Chen-Xiao Gao*, Dmitry Shribak*, Yitong Li, Chenjun Xiao, Bo Dai
- We leverages the flexibility of diffusion models by extracting diffusion spectral representations (Diff-SR) that capture the dynamics structure.
- Diff-SR is sufficient to represent the value function of any policy linearly, paving the way for efficient planning and exploration for diffusion-based RL.
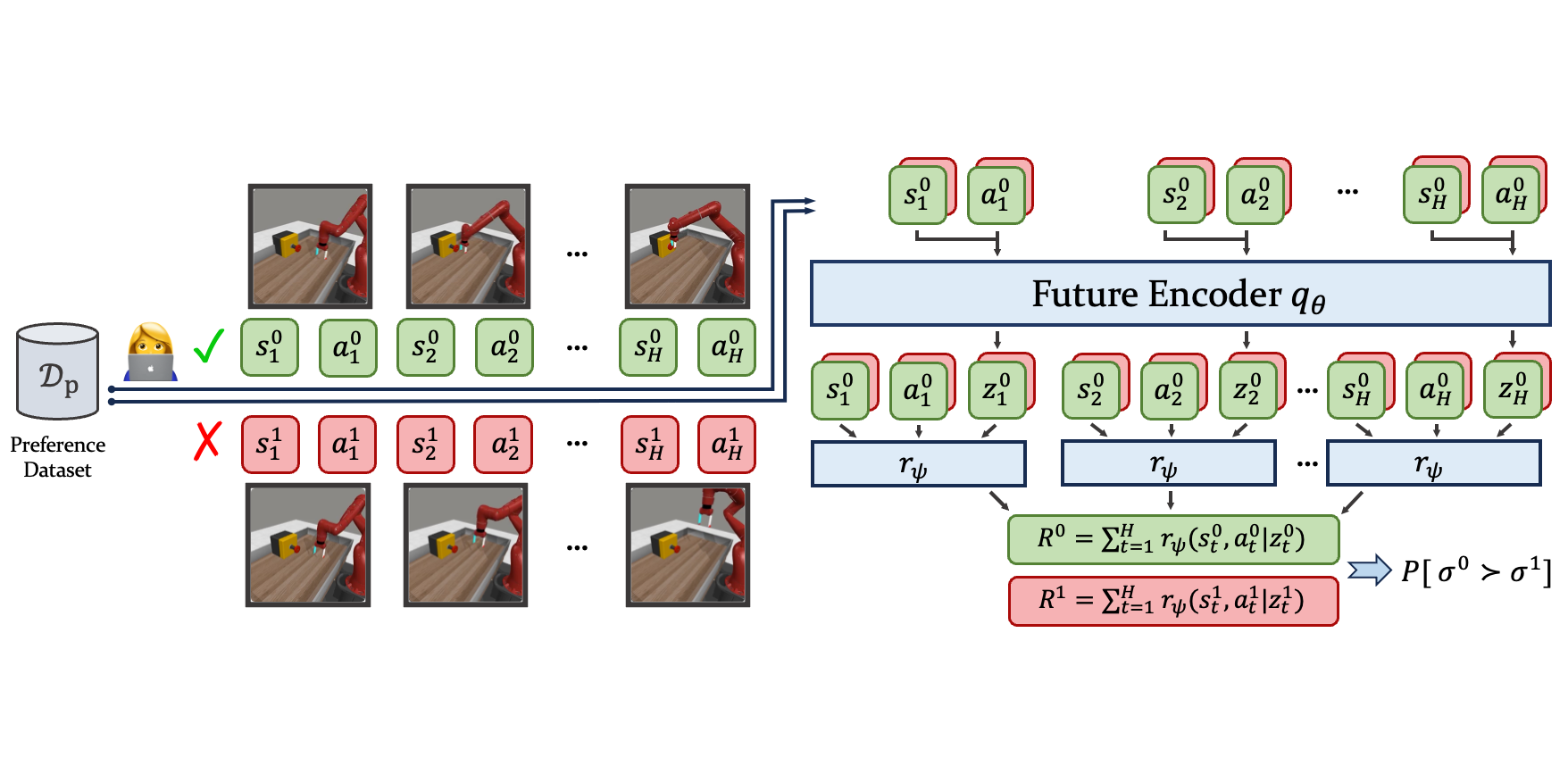
Hindsight Preference Learning for Offline Preference-based Reinforcement Learning
Chen-Xiao Gao, Shengjun Fang, Chenjun Xiao, Yang Yu, Zongzhang Zhang
- We identified shortages of the widely used preference modeling method in existing PbRL settings.
- HPL leverages the vast unlabeled dataset to facilitate credit assignment, providing robust and advantageous rewards for down-steam RL optimization.
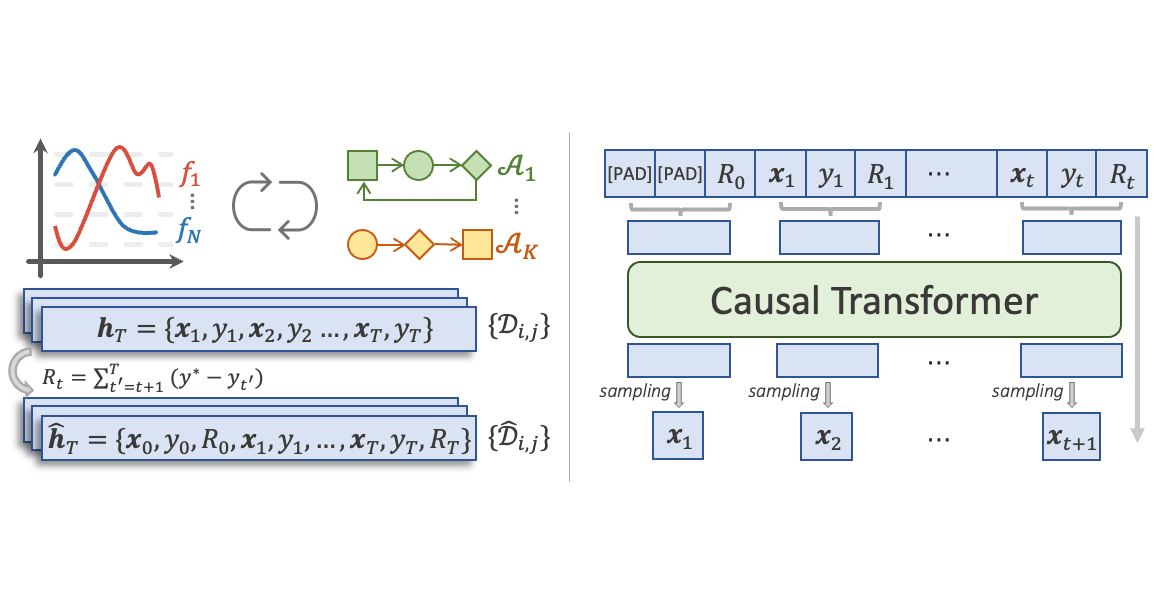
Reinforced In-Context Black-Box Optimization
Lei Song*, Chen-Xiao Gao*, Ke Xue, Chenyang Wu, Dong Li, Jianye Hao, Zongzhang Zhang, Chao Qian
- RIBBO distills and reinforces existing black-box optimization algorithms by fitting regret augmented learning histories of the behavior algorithms.
- By specifying a suitable regret-to-go, RIBBO generate better query decisions by auto-regressively predicting the next points.
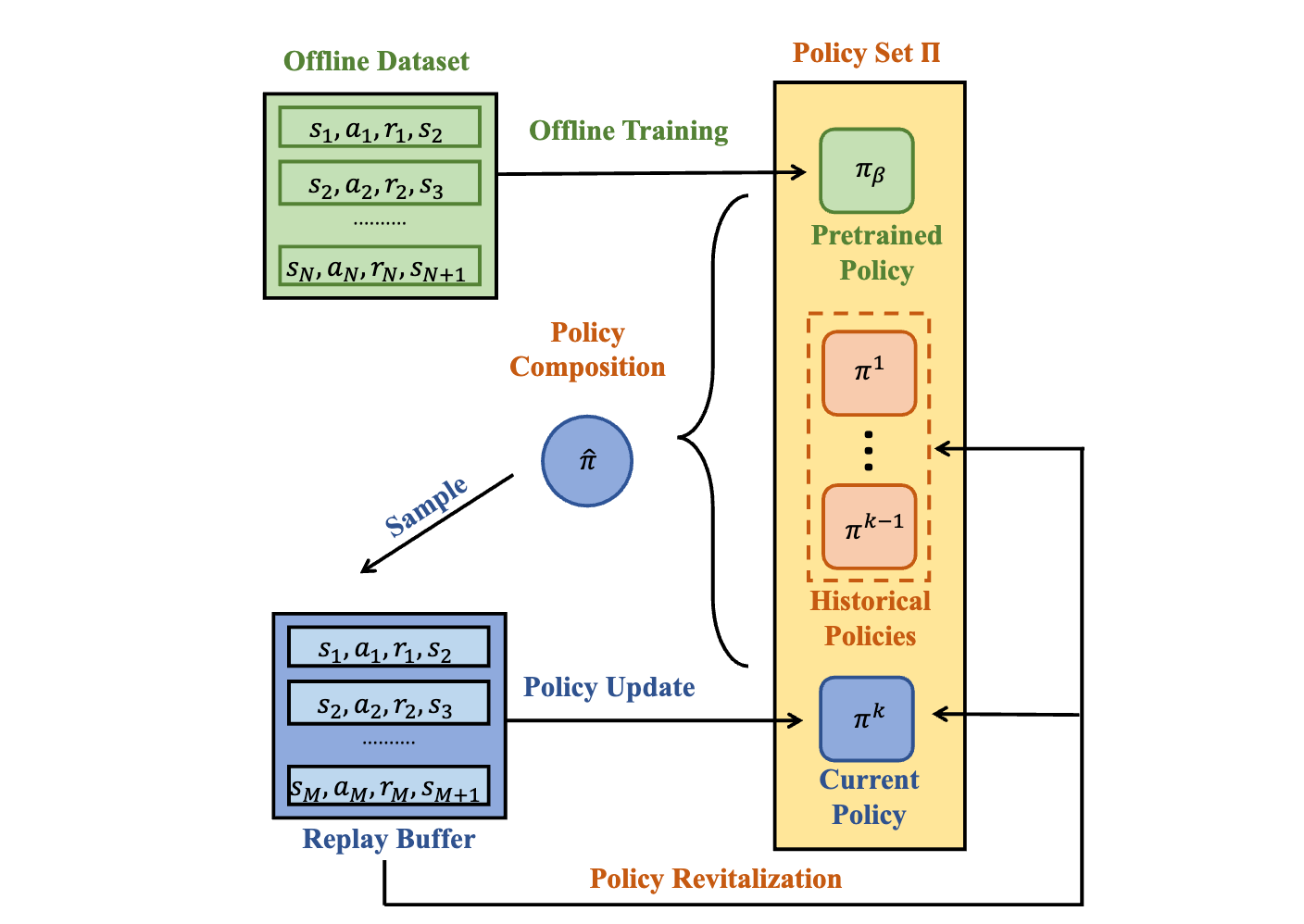
Efficient and Stable Offline-to-online Reinforcement Learning via Continual Policy Revitalization
Rui Kong, Chenyang Wu, Chen-Xiao Gao, Yang Yu, Zongzhang Zhang
- We identify two pain points in offline-to-online reinforcement learning: 1) value overestimation causes fluctuations during learning, and 2) the primacy bias hinders the policy from further improvement.
- With the proposed Continual Policy Revitalization, we can fine-tune pret-rained policies efficiently and stably.
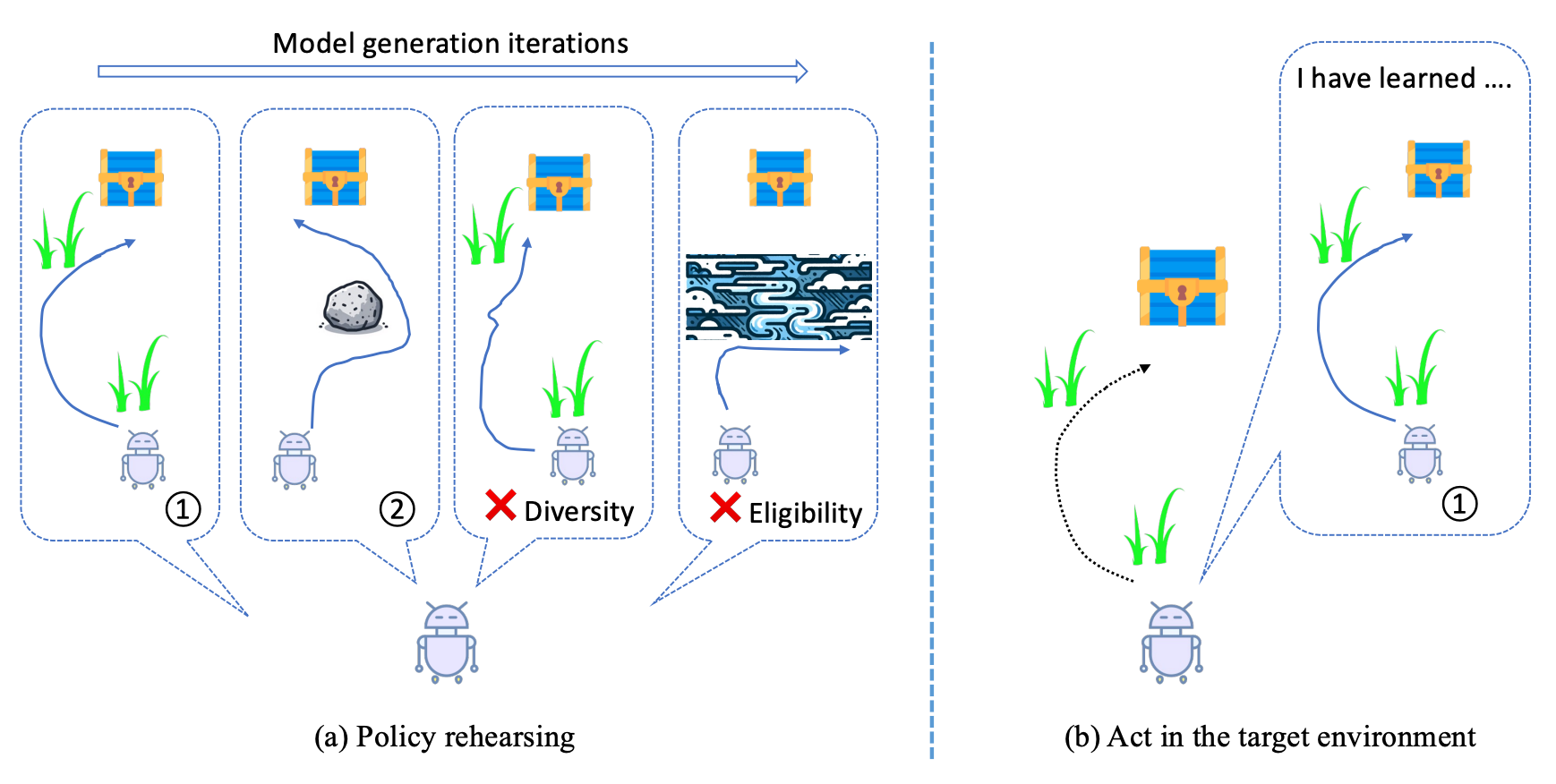
Policy Rehearsing: Training Generalizable Policies for Reinforcement Learning
Chengxing Jia*, Chen-Xiao Gao*, Hao Yin, Fuxiang Zhang, Xiong-Hui Chen, Tian Xu, Lei Yuan, Zongzhang Zhang, Yang Yu, Zhi-Hua Zhou
- We explore the idea of rehearsal for offline reinforcement learning, which generates diverse while eligible dynamics models using extremely limited amount of data and optimizes an contextual policy with the generated models.
- By recognizing the context, the policy is able to generalize to the environment at hand during the online stage.
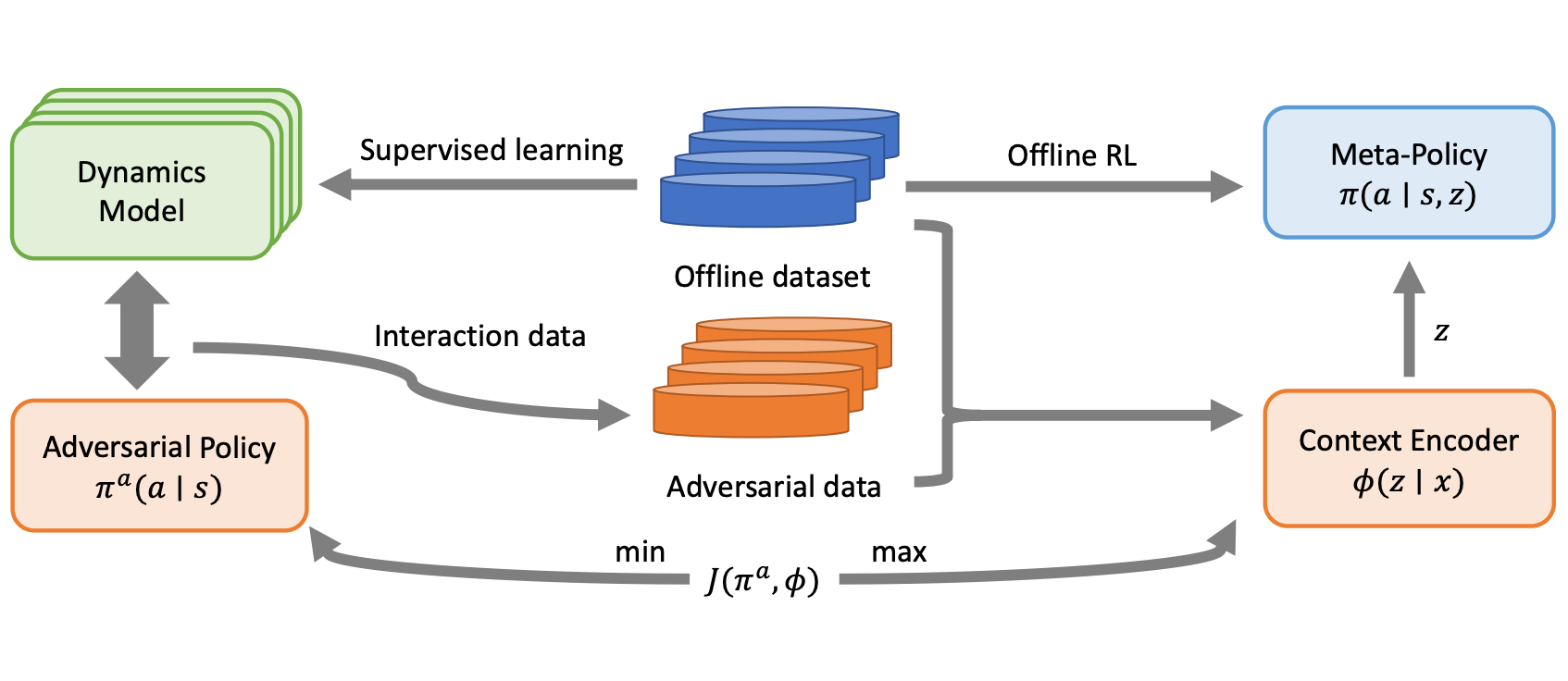
Disentangling Policy from Offline Task Rpresentation Learning via Adversarial Data Augmentation
Chengxing Jia, Fuxiang Zhang, Yi-Chen Li, Chen-Xiao Gao, Xu-Hui Liu, Lei Yuan, Zongzhang Zhang, Yang Yu.
- Learned task representations from previous OMRL methods tend to correlate spuriously with the behavior policy instead of the task.
- We disentangle the effect of behavior policies from representation learning by adversarial data augmentation.
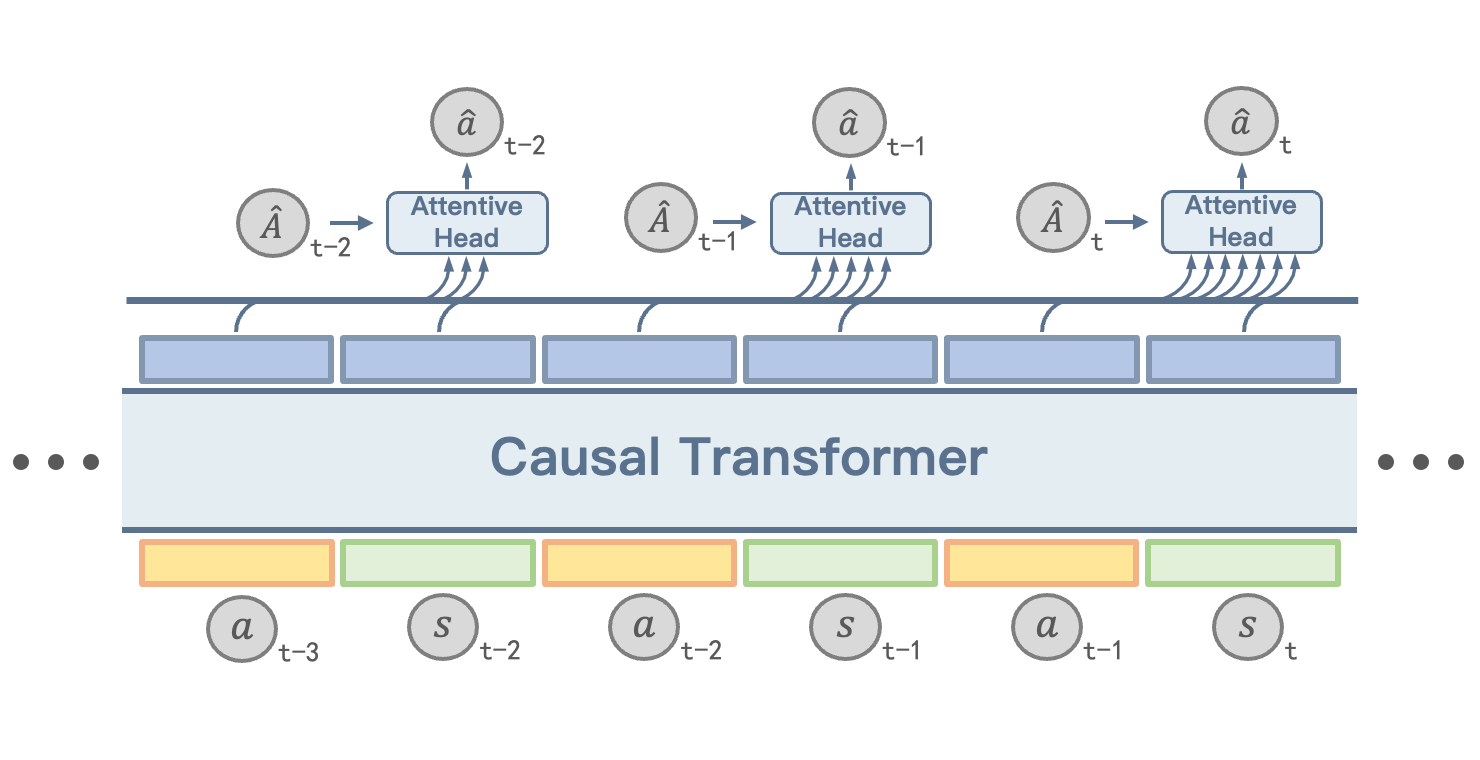
ACT: Empowering Decision Transformer with Dynamic Programming via Advantage Conditioning
Chen-Xiao Gao, Chenyang Wu, Mingjun Cao, Rui Kong, Zongzhang Zhang, Yang Yu
- We identify failure modes of existing return-conditioned decision-making systems, and suggest to use advantages as the property token for conditional generation.
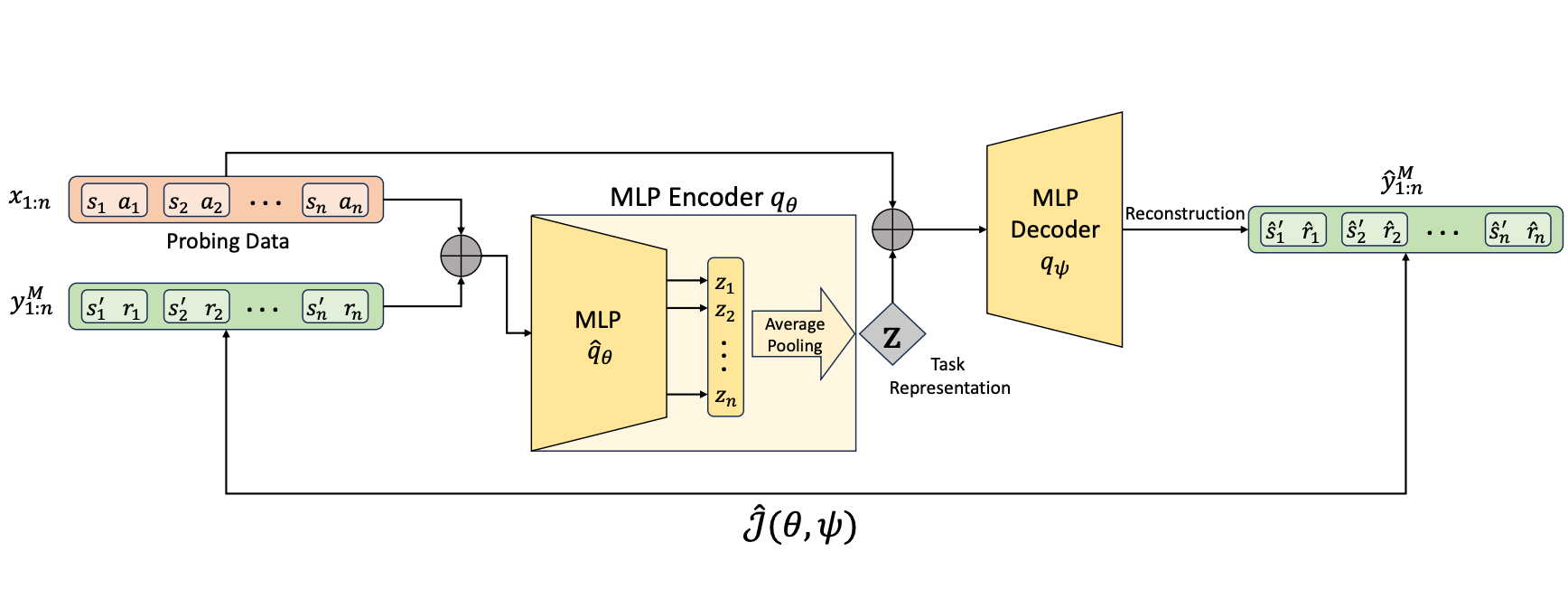
Renzhe Zhou, Chen-Xiao Gao, Zongzhang Zhang, Yang Yu
- Real-world RL applications are with data limitations, such as limited tasks and limited behavior diversity.
- We develop GENTLE, a simple yet effective task representation learning method to extract generalizable and accurate task representations from offline contextual datasets.
🎖 Honors and Awards
- 2022.06 Outstanding Graduate of School of AI, Nanjing University
- 2021.12 National Scholarship
- 2020.10 Chow Tai Fook Scholarship
- 2020.10 People’s Scholarship of Nanjing University
- 2019.10 Scholarship of School of AI, Nanjing University
📖 Educations
- 2022.09 - now, School of AI, Nanjing University
- 2018.09 - 2022.06, Computer Science, Nanjing University